ESXTOP CPU metrics
ESXTOP ESXi hypervisor için geliştirilmiş, hypervisor üzerindeki processleri interaktif bir şekilde inceleyebileceğimiz, kaynak kullanımlarını ve processlerin sistem genelinde nasıl davrandığına dair çıkarımlarda bulunabileceğimiz derinlemesine metrikler içeren built-in bir kernel modülüdür. ESXTOP temel olarak üç farklı modda çalışabilir, Gerçek Zamanlı (interaktif), Batch ( İstatistik toplayıp dosyaya kaydetme), Replay (kaydedilen istatistiği oynatma). Sonuç olarak esxtop için, Linux işletim sistemlerindeki top’ın vSphere için özelleştirilmiş versiyonu dersek yanlış olmaz.
Burada ESXi üzerinde CPU darboğaz yaşayıp yaşamadığımızı, hangi sütunu nasıl yorumlamamız gerektiği konusunu işliyor olacağım.
Öncelikle başlamadan önce “Prod” olarak nitelendirilen ortamlarda ve konsolide edilen iş yükleri barındıran yerlerde gerçek performans isteniyorsa, ESXi kurulumundan hemen sonra CPU C ve P state’leri kapatmanızı power saving adına donanım tarafında tüm özellikleri “disabled” duruma çekerek ESXi hostu “static high performance” modda çalıştırmanızı önemle tavsiye ederim.
ESXTOP Nasıl Çalıştırılır?
ESXi host’un SSH servisini çalıştırdıktan sonra Putty (öneririm!) tarzı bir istemci ile bağlanarak shell’e düştüğümüzde “esxtop” yazarak enter’a basıyoruz karşımıza ikinci görseldeki ekran geliyor.
ESXTOP CPU Metrikleri
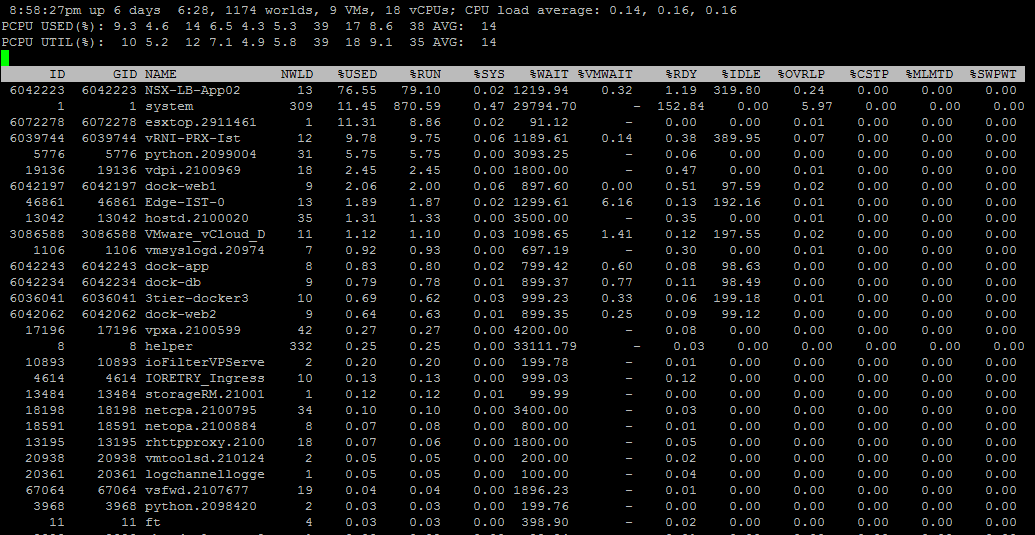
esxtop ekranında iken CPU metrikleri default olarak açılacaktır ancak örnek olarak memory ekranına gidip tekrar geri gelmek istediğimizde “c” harfine basmamız bizi CPU zamanı isteyen işlemlerin olduğu ekrana götürecektir. Burada karışık olarak ESXi servisleri ile birlikte Sanal Makine istatistikleride önümüze gelecektir. Sadece sanal makineleri filtrelemek için “Shift + v ” tuş kombinasyonunu kullanabilirsiniz.
ESXTOP CPU ekranında iken default statlar dışında ekstra statlar görmek için “f” tuşuna bastığınızda karşınıza üçüncü görsel ekranı gelecektir.
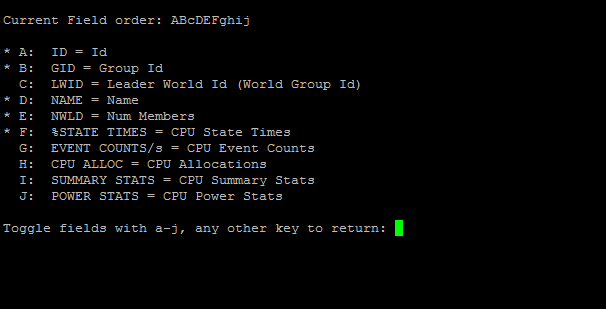
burada “shift + harf” kombinasyonu ile istenilen istatistikler işaretlendikten sonra enter’a basılarak tekrar CPU ekranına dönülür. Burada default olarak açık olmayan “SUMMARY STATS” ciddi önem arzetmektedir. “Shift + ı” kombinasyonu ile ilgili alanı açarak devam ediyorum.

Gördüğümüz üzere sütun sayımız bir hayli genişledi. İş artık neyi nasıl yorumlamamız gerektiğinde.
ESXTOP CPU Metrik Açıklamaları :
NWLD %USED %RUN %SYS %WAIT %VMWAIT %RDY %IDLE %OVRLP %CSTP %MLMTD %SWPWT %LAT_C %LAT_M %DMD EMIN TIMER/s
Performans analizi yaparken önem derecesine göre renklendirmeler şu şekilde olmalıdır.
Kritik
Çok Önemli
Normal
Gereksiz
Açıklamalar ;
NWLD
%USED
%RUN
%SYS
%WAIT
%VMWAIT
%RDY
%IDLE
%OVRLP
%CSTP
%MLMTD
%SWPWT
%LAT_C
%LAT_M
%DMD
EMIN
TIMER/s
Burada önem sırasına göre renklendirmeyi de yaptığıma göre ilgili bölümler için virten’den yararlanabiliriz : https://www.virten.net/vmware/esxtop/
Dikkat edilmesi gereken nokta şudur ki eğer CPU darboğazı yaşadığımızı düşünüyorsak bakmamız gereken noktalar yukarıda kırmızı ve turuncu ile işaret ettiklerim olmalı ki buralarda yüksek gördüğünüz değerlere karşı neler yapmalısınız buyrun;
Örnek Senaryo ;
HT sayesinde fiziksel core sayısından fazla vCPU atanabilse de yüksek utilization durumunda darboğaz oluşturabilir. VM’lere fiziksel core sayısını geçmeden atama yapmak performance best practice olarak değerlendirilebilir.Ama yine de iyi dağıtılmış bir vCPU yapısında 1 fiziksel core = 4 vCPU´a kadar oversubscription çok fazla göze batmayacaktır.
Örnek 24vCPU bir VM’i ele alalım. (Host CPU clock 2.0GHZ)
1 vcpu = 1 logical core’un GHZ degeri. 24 x 2.0 = 50 GHZ max clock rate. (contention oluştuğunda VM bu değere ulaşamayacaktır)
RUN = vCPU x 100. Mesela RUN degeri 1600 ise 16 cpu kullaniyor yani 32.0 GHZ.
RUN degeri USED’un altinda olmali. Bu durumda VMin istedigi CPU kaynagi core utilizasyonun altinda, yani baska VM ile yarisa girmeden hazir kaynağa ulaşabiliyor. Yani %OVRLP oluşmuyor.
LAT_C onemli – Buradaki yuzde ne kadar yüksek ise cpu clock rate congestion görülür. Mesela yüzde 33 ise 2000 x 0.33 = 660 MHZ congested durumda ve 24×660 = 15.840 MHz eder ki burada zaten 32.000 MHz bir atama yapılmıştı bu da demek ki VM’in hayatının yarısı ona atanan core’ları beklemekle geçiyor.
RDY de onemli. CPU basina ideal olarak yuzde 5’i geçmemelidir. Eğer RDY miktarı yüksek seviyelerde ise buna sebep olabilecek ilk iki durum içerisinde, İlgili VM’e yapılan gereğinden fazla vCPU ataması ve Hostta yapılan CPU oversubscribe durumları geçerlidir. Şunu tekrar hatırlatmak isterim ki FAZLA vCPU != FAZLA Performans.
VMWAIT’de cok onemli. Eğer diğer değerler süper ise fakat sadece VMWAIT yuksekse o zaman darboğaz OS/uygulama kaynakli yaşanıyor demektir.
%CSTP Bu değer incelenirken kullanmış olduğumuz application’ın çalışma mantığı çok önemlidir. İki durum mevcuttur burada senkronize iş parçacıkları ve asenkronize iş parçacıkları. İki durumu özetlemek gerekirse olay şöyle gerçekleşir;
Senkronize iş parçacık yapısı kullanan uygulama için; (single core)
Başlangıç ;
Zaman: 0:00:00: -> X işini başlat (İş 2 saniye sürecek)
Zaman: 0:00:02: -> Y işini başlat (İş 4 saniye sürecek)
Zaman: 0:00:06: ———> Y1 işini başlat (İş 3 saniye sürecek)
Zaman: 0:00:09: -> Z işini başlat (İş 8 saniye sürecek)
Bitiş : Toplam iş süresi sıralı işleneceğinden 17 saniye sürecektir.

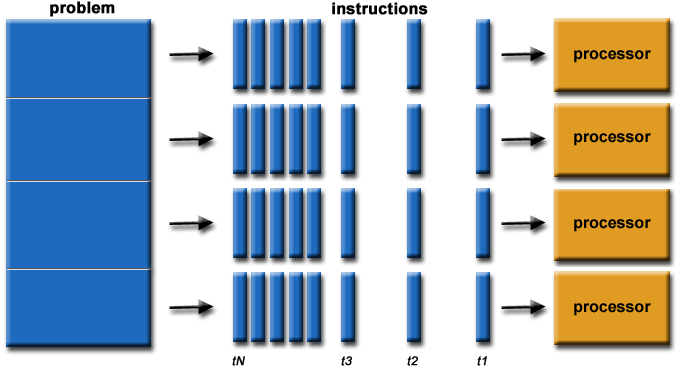
Senkronize iş parçacık yapısı kullanan uygulama için; (multicore)

Multicore yapısı için ise yukarıdaki görseldeki gibi iş/kod parçacıkları paralel olarak parçalanarak eş zamanlı olarak işlenir ve işin aynı zamanda bitirilmesi gerekir. Eğerki iş eş zamanlı bitmezse veya core’lardan birisi bekler durumda başka bir işle meşgul durumda kalırsa tüm diğer core’lar sistem kararlılığı için o iş bitene kadar beklemek durumundadır. Bu durum parallel processing ve symmetric processing gereğidir. Aşağıya örnek bir görsel bırakıyorum.
Asenkronize iş parçacık yapısı kullanan uygulama için;
Başlangıç ;
Zaman: 0:00:00: -> X işini başlat (İş 2 saniye sürecek) / Y işini başlat (İş 4 saniye sürecek) / Z işini başlat (İş 8 saniye sürecek)
Zaman: 0:00:04: —–> Y1 işini başlat (İş 3 saniye sürecek)
Bitiş : Toplam iş süresi bağımsız işler için X Y Z aynı anda başlayacağından en uzun işe göre (Z) 8 saniye olacaktır. (Y + Y1 = 7 saniyedir.)
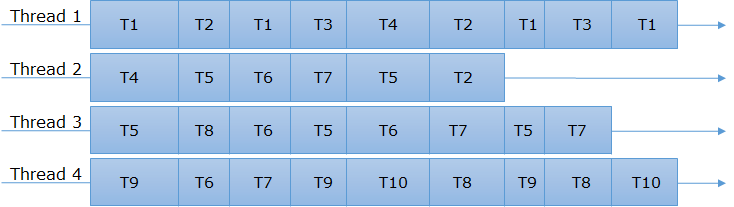
Peki yukarıdaki iki senaryoya göre tamamiyle utilize olan bir sistemde vCPU sayısını artırmak gerçekten ne etki yapacaktır?
Senkron iş yapısı için iş bağımlılığı olduğundan muhtemelen performans’a beklendiği gibi aşırı etkisi olmayacaktır çünkü bir işin başlaması için öncekinin bitiyor olması zorunludur ve daha fazla atama daha fazla potansiyel beklemedir.
Asenkron iş yapısı için iş bağımlılığı olmadığından mevcutta boşta olan tüm vCPU’lara iş parçaçığı gönderilecek ve runtime en uzun iş parçaçığına göre belirlenecektir. Bu durumda muhtemelen daha fazla vCPU daha fazla performans verebilecektir.
Peki nedir tüm bu RDY ve CSTP olayı?
Yukarıda Parallel processing durumunda anlattığım üzere ESXi Hypervisor CPU kaynaklarını VM’lere dağıtmak için vSMP (virtual symmetric processing) yapısı kullanmaktadır. Yani VM’den gelen iş yükleri, VM’e map edilen tüm vCPU’lara map edilip aynı anda işlemlerin bitmesi VM kararlılığı için gerektiğinden ve de Hypervisor doğası gereği dağıtık bir CPU mapping yaptığından bizler işler hızlansın diye bir VM’e gereken örnek 8vCPU’dan fazla 16vCPU verirsek gelen iş temel olarak 16 parçaya bölünüp dağıtılacak ve de hepsinin aynı anda bitmesi beklenecektir. Parçaçıkların aynı anlarda girip aynı anlarda çıkması çok önemlidir.
İşte tam olarak burada bizler hypervisor üzerinde bir VM’e gereğinden fazla vCPU dağıtırsak veya toplam fiziksel core sayımızın ideal olarak 3 katından fazlasını VM’lere atarsak RDY ve CSTP görmeye başlarız. Çünkü CPU scheduling yapılırken şunu düşünün; 2 fiziksel core var A ve B,
ve bu coreları utilize edecek 2 VM var. Birinci VM’den A üzerine gelen iş parçacığı B üzerine de gönderilecek ancak A core’u o sürede idle ve işi bitiriyor ancak B core’unda ikinci VM’in başka bir işi işleniyor.
Bu senaryoda birinci VM’e baktığınızda CSTP göreceksiniz çünkü A core’u işi bitirdi ve B core’unda paralel işin yapılmasını bekliyor.
Yine bu senaryoda birinci VM’e baktığınızda RDY göreceksiniz çünkü A core’u işi bitirdi sıradaki işi almak için bekliyor ancak B core’unda iş bekliyor ve onun tamamlanması gerekiyor. Bu durumda A core’u RDY durumda ama ikinci iş gelmiyor.
Sonuç olarak mevcut mimaride CSTP değeri için 3 maksimum RDY değeri için 5 maksimumları görmelisiniz. Eğer fazlasını görüyorsanız oturup VM’lere sizing yapmalı veya Fiziksel : vCPU oranını düşürmelisiniz.
Sonuç:
Sonuç olarak ESXTOP CPU metrikleri ile daha fazla haşır neşir olmak bizlere çok yardımcı olacaktır. Konu hakkında daha detaylı ve uzun yazmak istesemde bağımlı parametreler çok fazla olduğundan her birinden bahsetmem gerekmekte. Zaman buldukça bu tarz incelemeler yazmaya devam edeceğim. Açıklayamadığımı düşündüğünüz veya yanlış yazdığımı düşündüğünüz bir bölüm varsa bildirmenizi rica ederim.
Bu da görselimiz :









1 Response
[…] ESXTOP CPU metrics […]